[index]
00. Analysis background
01. 데이터 불러오기(w. pandas)
02. 데이터 살펴보기
03. 데이터 정제 (column 추가/제거)
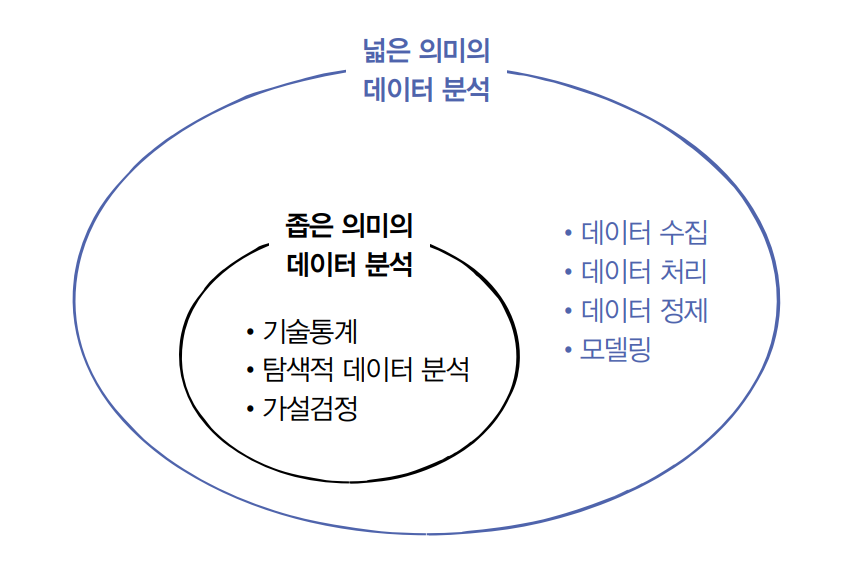
00. Analysis background
- 분석 목적
python을 활용한 RFM 분석을 통해 마케팅 전략을 수립하고자 함 - 데이터 정보
- 데이터 기간: 2020.10~2022.08
- 분석 시점: 2023.01
- 사용 모듈
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
01. 데이터 불러오기
df = pd.read_csv('파일 위치/customer_data.csv',sep='\t')- 파일 위치: data 폴더 안
- 파일명: customer_data.csv
- 파일 형태: csv
탭으로 구분된 파일이므로 sep 파라미터 추가 필요
02. 데이터 살펴보기
2-1. 데이터 크기 파악
customer_df.shape()2-2. 데이터 파악(1) - 샘플 보기
pd.set_option('display.max_columns',None)
customer_df.head()- 데이터 샘플 살펴보기
set_option()함수 사용 →display.max_columns옵션None설정 시, 모든 열 호출 가능
2-2. 데이터 파악(2) - 자료형 & 결측치 유무
customer_df.info()- 현재 데이터의 경우,
전체 row는 2,240개이나, 특정 컬럼에서 non-null count가 2,216개로 확인됨(=결측치 있음)
2-2. 데이터 파악(3) - 통계적 정보 확인
customer_df.describe(include='all')
2-2. 데이터 파악(4) - unique 값 확인
columns_object_dtype = customer_df.columns[customer_df.dtypes == 'object']
for col in columns_object_dtype:
unique_values = sorted(customer_df[col].unique())
print(f'{col}:{len(unique_values)}개')
print(unique_values, '\n')- object 형태의 column에 어떤 값들이 있는지 살펴보기
for문: object type의 열들에 어떤 unique 값이 있는지 확인columns_object_dtype변수: 자료형이 object인 컬럼만 불러오도록 설정unique_values변수:unique()함수를 사용해 중복 없이 값 불러오기f-string: 문자열에 변수 값 삽입print(unique_values, '\n'): 각 칼럼별 줄 바꿈해서 결과 보기
3. 데이터 정제
3-1. Column 결측값 처리
customer_df = customer_df.dropna()
customer_df.isna().sum()dropna(): 결측값 있는 row 삭제isna().sum(): 결측값 있는 row 개수
3-2. 필요 형태로 Column 가공/추가(1)
customer_df['birth_year'] = 2023 - customer_df['birth_year']
customer_df = customer_df.rename(columns={'birth_year': 'age'})
customer_df- 목적
birth_year 칼럼을 나이로 활용하고자 함 - 로직
- 현재 시점 (2023)에서 birth_year 뺀 값을 birth_year 칼럼에 바꿔 넣어주고
- age로 칼럼명 변경
3-2. 필요 형태로 Column 가공/추가(2)
data_amount_total = (
customer_df['amount_alcohol']
+ customer_df['amount_fruit']
+ customer_df['amount_meat']
+ customer_df['amount_fish']
+ customer_df['amount_snack']
+ customer_df['amount_general']
)
index_amount_general = customer_df.columns.get_loc('amount_general')
customer_df.insert(
loc = index_amount_general + 1,
column='amount_total',
value=data_amount_total,
)- 목적
결제값 total 칼럼 추가 - 로직
data_amount_total변수: 모든 결제값을 더해서 넣어줌amount_general칼럼 뒤에 넣고자index_amount_general변수에 현재amount_general칼럼의 위치 넣어줌insert()함수a. `loc`: 몇 번째 열에 넣을건지 b. `column`: 칼럼명 c. `value` : 해당 칼럼에 들어갈 데이터
3-3. 불필요 컬럼 제거
customer_df['annual_income'].describe()
customer_df['revenue'].describe()
customer_df = customer_df.drop(columns=['revenue'])
customer_df.head()- 목적
분석에 필요 없는 컬럼 확인 및 제거 - 로직
1.revenue는 평균,max, min이 모두 11인 것으로 확인됨 = 자료 분석 시 활용 불가drop():revenue칼럼 제거
'Base > Python' 카테고리의 다른 글
| 1-1. 데이터 분석, 어떤걸 먼저 배워야 하나요? (SQL, 파이썬, R) (0) | 2024.02.25 |
|---|